Welcome to .NET Tutorials. The objective of these tutorials is to get an in-depth understanding of .NET. The tutorial starts with an overview of .NET.
In addition to these tutorials, we will also cover common issues, Interview questions, and How To’s of MongoDB.
.NET is both a business strategy from Microsoft and its collection of programming support for what are known as Web services, the ability to use the Web rather than your own computer for various services. Microsoft's goal is to provide individual and business users with a seamlessly interoperable and Web-enabled interface for applications and computing devices and to make computing activities increasingly Web browser-oriented. The .NET platform includes servers; building-block services, such as Web-based data storage; and device software. It also includes Passport, Microsoft's fill-in-the-form-only-once identity verification service.
These core tutorials will help you to learn the fundamentals of .NET. For an in-depth understanding and practical experience, explore Online ".NET Training"
The Microsoft .NET initiative is a very wide initiative and it spans multiple Microsoft Products ranging from the Windows OS to the Developer Tools to the Enterprise Servers. The definition of .NET differs from context to context, and it becomes very difficult for you to interpret the .NET strategy. This section aims at demystifying the various terminologies behind .NET from a developer’s perspective. It will also highlight the need for using this new .NET Platform in your applications and how .NET improves over its previous technologies.
Windows DNA is a concept for building distributed applications using the Microsoft Windows operating system and related software products.
First, we will understand the 2- tier, 3- tier, and then move on to N- tier Windows DNA.
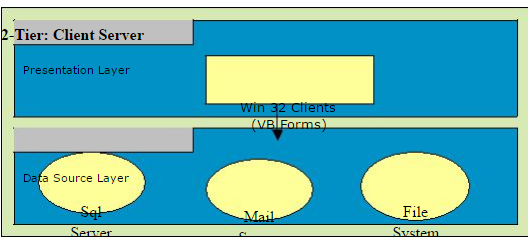
Through the appearance of Local-Area-Networks, PCs came out of their isolation, and were soon not only being connected mutually but also to servers. Client/Server- computing was born. A two-tiered application is an application whose functionality can only be segmented into two logical tiers, presentation services, and data services. The presentation services of a two-tiered application are responsible for gathering information from the user, interacting with the data services to perform the application's business operations, and presenting the results of those operations to the user. The Presentation services are also called the presentation layer because it presents information to the user. Things you might find in a presentation layer include a Web browser, a terminal, a custom-designed GUI, or even a character-based user interface. The client-Server architecture was a major buzzword in the early '90s, taking initially dumb terminal applications and giving them a fancy windows-like front end, using PCs with terminal emulators which presented pretty GUIs (Graphical user interface) or later Visual Basic, etc front-ends. A web browser talking to a web server is an example of a client talking to a server. Here there is presentation logic (presentation tier) happening at the client, and data/file access (data access tier) and logic happening at the server. One reason why the the2-tier model is so widespread is because of the quality of the tools and middleware that has been most commonly used since the ’90s: Remote-SQL, ODBC, relatively inexpensive, and well-integrated PC-tools (like Visual Basic, Power-Builder, MS Access,4-GL-Tools by the DBMS manufactures). In comparison, the server-side uses relatively expensive tools. In addition, the PC-based tools show good Rapid-Application-Development (RAD) qualities i.e. simpler applications can be produced in a comparatively short time. The 2-tier model is the logical consequence of RAD-tools popularity.
Tier: Client Server
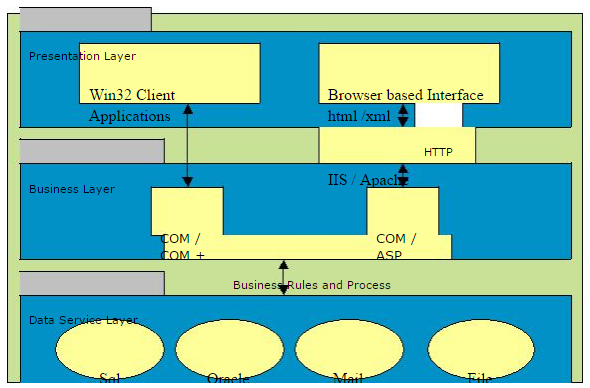
In a three-tiered application, the presentation services are responsible for gathering information from the user, sending the user information to the business services for processing, receiving the results of the business services processing, and presenting those results to the user. The most popular architecture on the web currently, mostly taking the form of web browser processing client side presentation in the form of HTML/DHTML, etc, the webserver using some scripting language (ASP) and the database server (SQL Server for example) serving up the data.
The basic functionalities of 3 – Tier or N-Tier follows are
The presentation services tier is responsible for:
-Gathering information from the user
-Sending the user information to the business services for processing
-Receiving the results of the business services processing
-Presenting those results to the user
The business services tier is responsible for:
-Receiving input from the presentation tier.
-Interacting with data services to perform business operations.
-Sending the processed results to the presentation tier.
The data services tier is responsible for the:
-Storage of data.
-Retrieval of data.
-Maintenance of data.
-Integrity of data.
In Windows DNA applications commonly implement their business logic using one or more of three implementation options.
-Asp Pages
-COM components
-Stored procedures running in the DBMS
Writing much business logic in ASP pages is a bad idea. Since simple languages are used, such as Microsoft Visual Basic Script, and the code is interpreted each time it is executed, which hurts the performance. Code in ASP pages is also hard to maintain, largely because business logic is commonly intermixed with presentation code that creates the user interface.
One recommended approach for writing middle-tier business logic is to implement that logic as COM objects. This approach is a bit more complex than writing a pure ASP application. Wrapping business logic in COM objects also cleanly separates this code from the presentation code contained in ASP pages, making the application easier to maintain.
The Third option for writing business logic is to create some of that code as stored procedures running in the database management system (DBMS). Although a primary reason for using stored procedures is to isolate the details of database schema from business logic to simplify code management and security, having code in such close proximity to data can also help optimize performance.
DLL Hell
DLLs gave developers the ability to create function libraries and programs that could be shared with more than one application. Windows itself was based on DLLs. While the advantages of shared code modules expanded developer opportunities, it also introduced the problem of updates, revisions, and usage. If one program relied on a specific version of a DLL, and another program upgraded that same DLL, the first program quite often stopped working.
Microsoft added to the problem with upgrades of some system DLLs, like comctl.dll, the library used to get file, font, color and printing dialog boxes. If things weren't bad enough with version clashes, if you wanted to uninstall an application, you could easily delete a DLL that was still being used by another program.
Recognizing the problem, Microsoft incorporated the ability to track usage of DLLs with the Registry starting formally with Windows 95, and allowed only one version of a DLL to run in memory at a time. Adding yet another complication, when a new application was installed that used an existing DLL, it would increment a usage counter. On uninstall, the counter would be decremented and if no application was using the DLL, it could be deleted.
That was, in theory. Over the history of Windows, the method of tracking of DLL usage was changed by Microsoft several times, as well as the problem of rogue installations that didn't play by the rules--the result was called "DLL HELL", and the user was the victim.
Solving DLL hell is one thing that the .NET Framework and the CLR targeted. Under the .NET Framework, you can now have multiple versions of a DLL running concurrently. This allows developers to ship a version that works with their program and not worry about stepping on another program. The way .NET does this is to discontinue using the registry to tie DLLs to applications and by introducing the concept of an assembly.
On the .NET Platform, if you want to install an application in the client's place all you have to do is use XCopy which copies all the necessary program files to a directory on the client’s computer. And while uninstalling all you have to do is just delete the directory containing the application and your application is uninstalled.
An Assembly is a logical DLL and consists of one or more scripts, DLLs, or executables, and a manifest (a collection of metadata in XML format describing how assembly elements relate). Metadata stored within the Assembly is Microsoft's solution to the registry problem. On the .NET Platform programs are compiled into
.NET PE (Portable Executable) files. The header section of every .NET PE file contains a special new section for Metadata (This means Metadata for every PE file is contained within the PE file itself thus abolishing the need for any separate registry entries). Metadata is nothing but a description of every namespace, class, method, property, etc. contained within the PE file. Through Metadata you can discover all the classes and their members contained within the PE file.
Metadata describes every type and member defined in your code in a Multilanguage form. Metadata stores the following information:
Description of the assembly
-Identity (name, version, culture, public key).o The types that are exported.
-Other assemblies that this assembly depends on.
-Security permissions needed to run
Description of types
Name, visibility, base class, and interfaces implemented.
Members (methods, fields, properties, events, nested types)
•Attributes
Additional descriptive elements that modify types and members
Advantages of Metadata:
Now let us see the advantages of Metadata:
Self-describing files:
CLR modules and assemblies are self-describing. The module's metadata contains everything needed to interact with another module. Metadata automatically provides the functionality of Interface Definition Language (IDL) in COM, allowing you to use one file for both definition and implementation. Runtime modules and assemblies do not even require registration with the operating system. As a result, the descriptions used by the runtime always reflect the actual code in your compiled file, which increases application reliability.
Language Interoperability and easier component-based design:
Metadata provides all the information required about compiled code for you to inherit a class from a PE file written in a different language. You can create an instance of any class written in any managed language (any language that targets the Common Language Runtime) without worrying about explicit marshaling or using custom interoperability code.
Attributes:
The .NET Framework allows you to declare specific kinds of metadata, called attributes, in your compiled file. Attributes can be found throughout the .NET Framework and are used to control in more detail how your program behaves at run time. Additionally, you can emit your own custom metadata into .NET Framework files through user-defined custom attributes.
Assembly
Assemblies are the building blocks of .NET Framework applications; they form the fundamental unit of deployment, version control, reuse, activation scoping, and security permissions. An assembly is a collection of types and resources that are built to work together and form a logical unit of functionality. An assembly provides the common language runtime with the information it needs to be aware of type implementations. To the runtime, a type does not exist outside the context of an assembly.
An assembly does the following functions:
-It contains the code that the runtime executes.
-It forms a security boundary. An assembly is a unit at which permissions are requested and granted.
-It forms a type boundary. Every type’s identity includes the name of the assembly at which it resides.
-It forms a reference scope boundary. The assembly manifest contains assembly metadata that is used for resolving types and satisfying resource requests. It specifies the types and resources that are exposed outside the assembly.
-It forms a version boundary. The assembly is the smallest versionable unit in the common language runtime; all types and resources in the same assembly are versioned as a unit.
-It forms a deployment unit. When an application starts, only the assemblies the application initially calls must be present. Other assemblies, such as localization resources or assemblies containing utility classes, can be retrieved on demand. This allows applications to be kept simple and thin when first downloaded.
-It is a unit where side-by-side execution is supported.
Contents of an Assembly
-Assembly Manifest
-Assembly Name
-Version Information
-Types
-Locale
-Cryptographic Hash
-Security Permissions
Assembly Manifest
Every assembly, whether static or dynamic, contains a collection of data that describes how the elements in the assembly relate to each other. The assembly manifest contains this assembly metadata. An assembly manifest contains the following details:
Identity. An assembly's identity consists of three parts: a name, a version number, and an optional culture.
File list. A manifest includes a list of all files that make up the assembly.
Referenced assemblies. Dependencies between assemblies are stored in the calling assembly's manifest. The dependency information includes a version number, which is used at run time to ensure that the correct version of the dependency is loaded.
Exported types and resources. The visibility options available to types and resources include "visible only within my assembly" and "visible to callers outside my assembly."
Permission requests. The permission requests for an assembly are grouped into three sets: 1) those required for the assembly to run, 2) those that are desired but the assembly will still have some functionality even if they aren't granted, and 3) those that the author never wants the assembly to be granted.
In general, if you have an application comprising of an assembly named Assem.exe and a module named Mod.dll. Then the assembly manifest stored within the PE Assem.exe will not only contain metadata about the classes, methods, etc. contained within the Assem.exe file but it will also contain references to the classes, methods etc, exported in the Mod.dll file. While the module Mod.dll will only contain metadata describing itself.
The following diagram shows the different ways the manifest can be stored:

For an assembly with one associated file, the manifest is incorporated into the PE file to form a single-file assembly. You can create a multifile assembly with a standalone manifest file or with the manifest incorporated into one of the PE files in the assembly.
The Assembly Manifest performs the following functions:
-Enumerates the files that make up the assembly.
-Governs how references to the assembly's types and resources map to the files that contain their declarations and implementations.
-Enumerates other assemblies on which the assembly depends.
-Provides a level of indirection between consumers of the assembly and the assembly's implementation details.
-Renders the assembly self-describing.
Modules are also PE files (always with the extension .netmodule) which contain Metadata but they do not contain the assembly manifest. And hence in order to use a module, you have to create a PE file with the necessary assembly manifest.
In C#, you can create a module using the /t:module compiler switch.
There are a few ways to incorporate a module into an Assembly. You can either use /addmodule switch to add module/s to your assembly, or you can directly use the /t:exe, /t:winexe and /t:library switches to convert the module into an assembly.
Difference between Module and Assembly
A module is an .exe or .dll file. An assembly is a set of one or more modules that together make up an application. If the application is fully contained in a .exe file,fine—that's a one-module assembly. If the .exe is always deployed with two .dll files and one thinks of all three files as comprising an inseparable unit, then the three modules together form an assembly, but none of them does so by itself. If the product is a class library that exists in a .dll file, then that single .dll file is an assembly. To put it in Microsoft's terms, the assembly is the unit of deployment in
.NET.
An assembly is more than just an abstract way to think about sets of modules. When an assembly is deployed, one (and only one) of the modules in the assembly must contain the assembly manifest, which contains information about the assembly as a whole, including the list of modules contained in the assembly, the version of the assembly, its culture, etc.
When compiling to managed code, the compiler translates your source code into Microsoft intermediate language (MSIL), which is a CPU-independent set of instructions that can be efficiently converted to native code. MSIL includes instructions for loading, storing, initializing, and calling methods on objects, as well as for instructions for arithmetic and logical operations, control flow, direct memory access, exception handling, and other operations. Before code can be executed, MSIL must be converted to CPU-specific code by a just-in-time (JIT) compiler. Because the runtime supplies one or more JIT compilers, for each computer architecture it supports, the same set of MSIL can be JIT-compiled and executed on any supported architecture.
When a compiler produces MSIL, it also produces metadata. The MSIL and metadata are contained in a portable executable (PE file) that is based on and extends the published Microsoft PE and Common Object File Format (COFF) used historically for executable content. This file format, which accommodates MSIL or native code as well as metadata, enables the operating system to recognize common language runtime images. The presence of metadata in the file along with the MSIL enables your code to describe itself, which means that there is no need for type libraries or Interface Definition Language (IDL). The runtime locates and extracts the metadata from the file as needed during execution.
Debugging is the most important feature of any programming language and Visual Studio
.NET IDE provides this feature in an effective manner (but you can still do a pretty good job with the .NET SDK alone). The application source code goes through two distinct steps before a user can run it. First, the source code is compiled to Microsoft Intermediate Language (MSIL) code using a .NET compiler. Then, at runtime, the MSIL code is compiled to native code. When we debug a .NET application, this process works in reverse. The debugger first maps the native code to the MSIL code. The MSIL code is then mapped back to the source code using the programmer's database (PDB) file. In order to debug an application, these two mappings must be available to the .NET runtime environment.
To accomplish the mapping between the source code and the MSIL, use the/debug:pdbonly compiler switch to create the PDB file (Note: When building ASP.NET applications, specify the compilation setting debug="true" in the application’s Web.config file). The second mapping between the MSIL code and native code is accomplished by setting the JITTracking attribute in our assembly. By specifying the /debug compiler switch, the PDB file is created and the JITTracking attribute is enabled. When using this compiler switch, a debugger can be attached to an application loaded outside of the debugger.
Once the required mappings exist, there are several means by which to debug our applications. We can use the integrated debugger within Visual Studio .NET, or, if we prefer, we can use DbgClr, a GUI-based debugger. There is also a command-line debugger, CorDBG that is included in the .NET Framework SDK.
-Newest technology from MS for app development
-Supports fully managed, but also a hybrid mix of managed and native through P/Invoke and Managed/Unmanaged C++, which means that its easier to write code that doesn't have lots of memory leaks
-WPF and WCF are the new way of building UI's and Communicating between processes and systems
-Fully integrated IDE available
-Linux and Mac support through 3rd parties (Mono)
-Many languages available, both dynamic (IronPython and IronRuby) and static (C#, VB.NET, C++), both object-oriented (C#, VB.NET, C++) and functional (F#)
- Multi-platform support isn't available from MS and isn't available straight after installing Visual Studio - Managed code can be slower than native code
Application domains offer all the benefits of process isolation but are much more efficient than processes. The Microsoft .NET runtime host automatically manages the loading/unloading of the assemblies into the appropriate application domains. However, Microsoft .NET Framework class library also offers application developers with various classes that can be used to programmatically create application domains and ensure that the various applications can be isolated from each other. Also, inter-application communication is not that expensive because context switching is not involved in application communication using application domains in Microsoft .NET.
You liked the article?
Like: 0
Vote for difficulty
Current difficulty (Avg): Medium

TekSlate is the best online training provider in delivering world-class IT skills to individuals and corporates from all parts of the globe. We are proven experts in accumulating every need of an IT skills upgrade aspirant and have delivered excellent services. We aim to bring you all the essentials to learn and master new technologies in the market with our articles, blogs, and videos. Build your career success with us, enhancing most in-demand skills in the market.

