Welcome to SAP HANA Tutorial. The objective of these tutorials is to gain an in-depth understanding of SAP HANA. In this tutorial, we will cover topics such as SAP HANA Architecture, Data Modeling, Replication, Creating Views, Joins etc. In addition to the SAP HANA tutorial, we will cover common interview questions and issues of SAP HANA.
Product Artifacts SAP BW 7.3 (BW Data) SAP ECC (Transaction data) BOB 4.0 (Reporting tool) DS 4.0 (ETL) SYBASE (Replication Agent) NON SAP OLAP (data sources)
HANA database – Place to prepare Hybrid Database HANA Studio – Modeling And Administration HANA information Composer – Web Based Modeling
Functional: Enable end-user to do ‘Near” real-time reporting from ASP/NONSAP ERP systems. (‘Near Real-time’ – To get updated data subsequently)
Example: For Every Minute
![]() Enable Process Oriented BI from SAP BW/NONSAP DLAP data sources
Enable Process Oriented BI from SAP BW/NONSAP DLAP data sources
![]() To create a Hybrid In-Memory database using the Advance process
To create a Hybrid In-Memory database using the Advance process
Technical:
Landscape:

We have, Source systems such as SAP ERP, NON-SAP ERP, BW & And Non SAP OLAP
![]() We can retrieve data from data providers to SAP HANA by performing replication
We can retrieve data from data providers to SAP HANA by performing replication
![]() There are 3 types of replications to retrieve data from data providers.
There are 3 types of replications to retrieve data from data providers.
Trigger-based Replication ETL based Replication Log-based Replication

Using SAP Landscape Transformation (LT) Replication Server is based on capturing database changes at a high level of abstraction in the source ERP system. This method of replication benefits from being database – independent, and can also parallelize database changes on multiple tables or by segmenting large table changes.

Extraction – Transformation – Load (ETL) Based Data Replication Uses SAP Business Objects Data Services to specify and load the relevant business data in defined periods of time from an ERP system into the Sap HANA database. You can reuse the ERP application logic by reading extractors or utilizing SAP function modules in addition, the ETL based method offers options for the integration of third-party data providers.

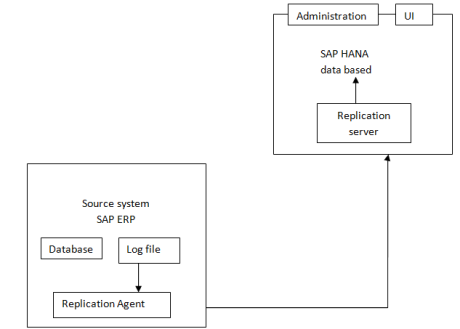
Transaction Log-based Data Replication Using Sybase Replication is based on capturing table changes from low-level database on files. This method is database dependent.
Database changes are propagated on a per-database transaction basis, and they are then replayed on the SAP HANA database. This means consistency is maintained but at the cost of not being able to use parallelization to propagate changes.
If the customer wants to use “ETL based replication” using Based he requires the following components
If the customer is planning to adopt “trigger-based” data replication from the HANA database then we require below
If the customer is planning to use log-based data replication he should use
Note 1: ETL &Trigger Level data replication is applied at replication level
Note 2: log-based’ replication is adopted at the table level.
SAP HANA DB
It comes along with Sap Appliance which has row store and column store data store which are maintained by different calculation and SQL engines
SAP HANA Studio
It will allow you to do
SAP HOST Agent
This is required to enable the start and stop of services in every computer system also it enables to do maintaining activates
SAP HANA DB Client
This is plug-in installed in the client system to give data inputs to HANA DB remotely
Information Composer
It is a web-based Utility where the enclosure can upload the data and to create quick data views which can be given as input to Microsoft Excel and to Bo X celosias for reporting
Load Controller
The load controller is a HANA API(Applicable Programmer) which resides an SAP HANA architecture that controls the replication process also it will take care of initial and data loads to HANA DB.
SAP HANA Landscape transformation
This Utility is used to monitor the data browsing when data is extracted from different ERP systems which help in bulk data transfer without any transformation which is used in BODS.
SYBASE Adaptive Serves
is an RDBMS system which is a utility of SYBASE to handle OLTP processing, XML documents, etc., (grain level) which also helps in real-time reporting, disasters recovery between source & target
BODS
BODS is an ERP utility which has a designer component which can connect to SAP ERP (SAP Application Datastore) which can load to SAP HANA Database as a target with normal data Haws or ABAP data flows (system generated)
To do the ETL process we should also configure Boos job server (Batch process) and Access Server (Real-time Process)

SAP HANA Interview Questions
What is SAP HANA?
SAP HANA is an in-memory database.
An in-memory database means all the data is stored in the memory (RAM). This is no time wasted in loading the data from hard-disk to RAM or while processing keeping some data in RAM and temporary some data on disk. Everything is in-memory all the time, which gives the CPUs quick access to data for processing. SAP HANA is equipped with a multi-engine query processing environment that supports relational as well as graphical and text data within the same system. It provides features that support significant processing speed, handles huge data sizes, and text mining capabilities.
What is the language SAP HANA is developed in?
The SAP HANA database is developed in C++.
What is the operating system supported by HANA?
Currently SUSE Linux Enterprise Server x86-64 (SLES) 11 SP1 is the Operating System supported by SAP HANA.
Can I just increase the memory of my traditional Oracle database to 2TB and get similar performance?
NO. You might have performance gains due to more memory available for your current Oracle/Microsoft/Teradata database but HANA is not just a database with bigger RAM. It is a combination of a lot of hardware and software technologies. The way data is stored and processed by the In-Memory Computing Engine (IMCE) is the true differentiator. Having that data available in RAM is just the icing on the cake.
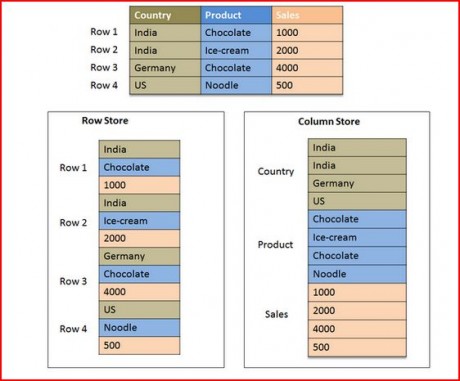
What are the row-based and column based approach?
Row based tables
It is the traditional Relational Database approach
It store a table in a sequence of rows
Column based tables
It store a table in a sequence of columns i.e. the entries of a column is stored in contiguous memory locations.
SAP HANA is particularly optimized for column-order storage.
SAP HANA supports both row-based and column-based approaches. Following figure explains the difference between the two storage mechanism.
What are the advantages and disadvantages of row-based tables?
Row based tables have advantages in the following circumstances:
-The application needs to only process a single record at one time (many selects and/or updates of single records).
-The application typically needs to access a complete record (or row).
-Neither aggregations nor fast searching are required.
-The table has a small number of rows (e. g. configuration tables, system tables).
Row based tables have dis-advantages in the following circumstances
-In case of analytic applications where aggregation are used and fast search and processing is required. In row based tables all data in a row has to be read even though the requirement may be to access data from a few columns.
What are the advantages of column-based tables?
In HANA which type of tables should be preferred - Row-based or Column-based?
SQL queries involving aggregation functions take a lot of time on huge amounts of data because every single row is touched to collect the data for the query response. In columnar tables, this information is stored physically next to each other, significantly increasing the speed of certain data queries. Data is also compressed, enabling shorter loading times.
Summary: To enable fast on-the-fly aggregations, ad-hoc reporting, and to benefit from compression mechanisms it is recommended that transaction data is stored in a column-based table. The SAP HANA data-base allows joining row-based tables with column-based tables. However, it is more efficient to join tables that are located in the same row or column store. For example, master data that is frequently joined with transaction data should also be stored in column-based tables.
How does SAP HANA support Massively Parallel Processing?
With availability of Multi-Core CPUs, higher CPU execution speeds can be achieved. Also HANA Column-based storage makes it easy to execute operations in parallel using multiple processor cores. In a column store data is already vertically partitioned. This means that operations on different columns can easily be processed in parallel. If multiple columns need to be searched or aggregated, each of these operations can be assigned to a different processor core. In addition operations on one column can be parallelized by partitioning the column into multiple sections that can be processed by different processor cores. With the SAP HANA database, queries can be executed rapidly and in parallel.
What is ad-hoc analysis?
In traditional data warehouses, such as SAP BW, a lot of pre-aggregation is done for quick results. That is the administrator (IT department) decides which information might be needed for analysis and prepares the result for the end users. This results in fast performance but the end user does not have flexibility. The performance reduces dramatically if the user wants to do analysis on some data that is not already pre-aggregated. With SAP HANA and its speedy engine, no pre-aggregation is required. The user can perform any kind of operations in their reports and does not have to wait hours to get the data ready for analysis.
For an Indepth knowledge on SAP HANA, click on below
You liked the article?
Like: 0
Vote for difficulty
Current difficulty (Avg): Medium

TekSlate is the best online training provider in delivering world-class IT skills to individuals and corporates from all parts of the globe. We are proven experts in accumulating every need of an IT skills upgrade aspirant and have delivered excellent services. We aim to bring you all the essentials to learn and master new technologies in the market with our articles, blogs, and videos. Build your career success with us, enhancing most in-demand skills in the market.

