QVD (QlikView Data) file is a file containing a table of data exported from QlikView. QVD is a native QlikView format and can only be written to and read by QlikView. The file format is optimized for speed when reading data from a QlikView script but it is still very compact. Reading data from a QVD file is typically 10-100 times faster than reading from other data sources.
QVD files can be read in two modes: standard (fast) and optimized (faster). The selected mode is determined automatically by the QlikView script engine. Optimized mode can be utilized only when all loaded fields are read without any transformations (formulas acting upon the fields), though the renaming of fields is allowed.
WHERE clause causing QlikView to unpack the records will also disable the optimized load.
A QVD file holds exactly one data table and consists of three parts:
-Increasing Load Speed: By buffering non-changing or slowly changing blocks of input data in QVD files, script execution becomes considerably faster for large data sets.
-Decreasing Load on Database Servers: The amount of data fetched from external data sources can also be greatly reduced. This reduces work load on external databases and network traffic. Furthermore, when several QlikView scripts share the same data it is only necessary to load it once from the source database into a QVD file. The other applications can make use of the same data via this QVD file.
- Consolidating Data from Multiple QlikView Applications: With the Binary script statement it is possible to load data from only one single QlikView application into another one, but with QVD files a QlikView script can combine data from any number of QlikView applications. This opens up possibilities e.g. for applications consolidating similar data from different business units etc.
Incremental Load: In many common cases the QVD functionality can be used for facilitating incremental load, i.e. exclusively loading new records from a growing database.
A QVD file can be created by one of three different methods
QlikView data eXchange (QVX): Files are used for data input from external systems into QlikView. The main difference with respect to the QVD file is that QVX is a public format and can be created from external interfaces. It can be considered as the format in which custom data sources send data to QlikView via the custom connector. Data retrieval becomes optimized when complying with QVX specifications, although not as optimized as QlikView's own QVD.
Joins in Script: Sometimes you need to join tables in the script, i.e. you use two or more tables as input, perform the join and get one table as output for the QlikView data model. It could be that you want to denormalize the data model to improve performance or that you, for some other reason, choose to put fields from two tables into one .
By default, QlikView performs an outer join. This means that the rows for both tables are included in the resulting table. When rows do not have a corresponding row in the other table, the missing columns are assigned null values.
When you join two tables, there is always a possibility that the number of records change. In most cases, this is not a problem – rather, it is exactly what you want. One example could be that you have a table containing order headers and one containing order details. Each header can have several order lines in the order details table. When these two tables are joined, the resulting table should have the same number of records as the order details table: you have a one-to-many relationship so an order can have several order lines, but an order line cannot belong to several order headers. The only problem you encounter is that you can no longer sum a number that resided in the order header table.
There are two ways to perform joins in the QlikView script:
The external join – the SQL SELECT join
A join can be defined inside a SELECT statement, which in the script execution is sent as a string to the connector, usually a relational database management system (RDBMS) using the ODBC or OLE DB connection. Then QlikView waits for an answer. In other words: the SQL join is performed on the DB system. This is sometimes more efficient and more robust than if you let QlikView manage it. This is especially true if you have large tables; then you should make the join inside the SELECT statement.
A join inside a SELECT statement is often versatile: you can make any type of join that the database allows, e.g. also joins that are not natural:
TableA.key >= TableB.Key
One consequence of letting the RDBM system manage the join is that the syntax of the SELECT statement may differ from database to database. QlikView does not interpret the SELECT statement. Instead it is evaluated by the RDBMS.
Examples of SELECT statements joining tables:
SELECT Customers.FirstName, Customers.LastName, SUM(Sales.SaleAmount) AS Sales PerCustomer FROM Customers
LEFT JOIN Sales ON Customers.CustomerID = Sales.CustomerID
GROUP BY Customers.FirstName, Customers.LastName;
SELECT suppliers.supplier_id, suppliers.supplier_name, orders.order_date
FROM suppliers, orders WHERE suppliers.supplier_id = orders.supplier_id;
The QlikView join – the Join prefix:
The Join prefix in the QlikView script joins the loaded table with one that has been loaded previously in the script run. It is performed by QlikView itself. Just as the associations, QlikView joins are natural joins based on that the two key fields are named the same. If there is no common key, the Cartesian product of the two tables will be generated.
The QlikView join is fast but will need a lot of primary memory. So if the tables are large, the performance may become poor. For smaller tables it is however the best alternative.
The JOIN statement can be prefixed with the statements INNER, OUTER, LEFT, and RIGHT, which performs an inner, outer, left, or right join respectively.
INNER JOIN: Only rows that can be matched between both tables will be kept in the result.
OUTER JOIN: All rows will be kept in the result; rows that do not have a corresponding value in the other table will get null values for the fields that are unique to that table. When no prefix is specified, this is the default join type that will be used.
LEFT JOIN: All rows from the first table and those rows from the second table that have a corresponding key in the first table, will be included in the result. When nomatch is found, null values will be shown for the columns that are unique to the second table.
RIGHT JOIN: All rows from the second table and those rows from the first table which have a corresponding key in the second table will be included in the result. When no match is found, null values will be shown for the columns that are unique to the first table.
Ex: Tab: load * Inline [ EmpNo, Name, Salary 1001, abc ,10000 1002, bcd ,20000 1003, cde ,25000 1004, def ,30000 1005, efg ,25000 ];
Join load * Inline [ EmpNo, Designation 1003, SE 1004, SE 1005, TL 1006, PM 1007, SSE 1008, ASE ]; Following is the result:
Default Join or Outer Join:
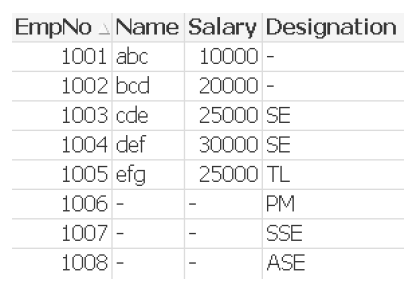
Inner Join:

Left Join:

Right Join:

When using just the bare JOIN statement, the join will be made to the table loaded directly before the JOIN statement. If the table to join to was loaded somewhere earlier in the script, that table can be joined to by supplying its name in parentheses. In our example this would be achieved by replacing JOIN with JOIN (Table1).
You liked the article?
Like: 0
Vote for difficulty
Current difficulty (Avg): Medium

TekSlate is the best online training provider in delivering world-class IT skills to individuals and corporates from all parts of the globe. We are proven experts in accumulating every need of an IT skills upgrade aspirant and have delivered excellent services. We aim to bring you all the essentials to learn and master new technologies in the market with our articles, blogs, and videos. Build your career success with us, enhancing most in-demand skills in the market.

