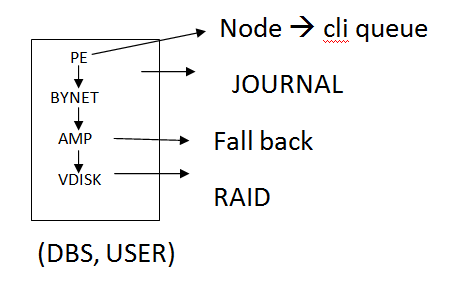
Locks:- Prevent simultaneous access to the objects
RAID:- Prevent from disk failure
Fall back:- Prevent from Amp failure
Journal:- Prevent from Image failure
CLIQUE:- Prevent from Node failure
A Means of Archiving data to tape and disk and restoring data to teradata database backup application software includes the following
Teradata archive and recovery, Net Valet, Net Backup, Tivoli Storage Manager, Teradata Extension.
Note:- the above all feature are provides teradata, to makes teradata as highly

|
LOCK Held |
Table Name |
“A” having Lock Access |
Read |
Write |
Exclusive |
|
Access |
√ | √ | √ | √ |
X |
|
Read |
√ | √ | √ |
X |
X |
|
Write |
√ | √ |
X |
X |
X |
|
Exclusive |
√ |
X |
X |
X |
X |
Inclined to build a profession as Teradata Developer? Then here is the blog post on, explore Teradata Training
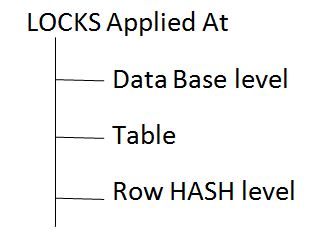
DATA Inconsistent, select
DATA consistent, select
Insert, Update, Delete
DDL Statement
Syntax- Locking row for
<Lock type><Sql Queue >
Example
Locking row for access SEL* From party Locking row for write SEL*from party
Syntax Table level
Locking table<Table name> for
<Lock type>
Example Locking table party for access
Syn Release Lock database name Table name:
a) Permit queue access to a table multiuser Environment
b) Having minimal blocking efforts on other queries
c) Very use full for aggregating a huge number of rows.
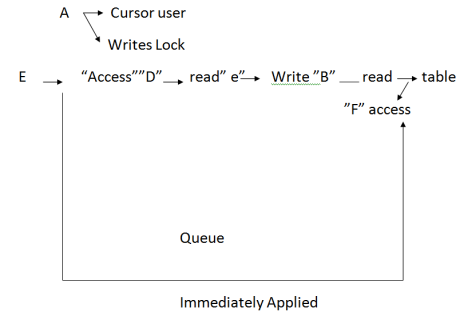
![]() Access Lock applied Immediately even though there are many locking it’s that query
Access Lock applied Immediately even though there are many locking it’s that query
Note- Refer to the complete description And practical page NO:50 to 52 new material
RAID-[REDUNDENT ARRAY OF INDEPENDENT DISK DRIVE] Refer to the page No: 53 To 54 for the description
RAIDO,RAID1,RAID2,------RAID5,RAIDS,RAIDE etc.,
RAID1, RAID5, RAIDS
RAID1:[MIRRORING TECHNIQUE] Real-time use
Advantage:-quick Availability, primary disk failure, recovers a/s easier

Drawback
RAID5:-[PARTY CHECKING TECHNIQUE]

P= B1+B2+B3
B1=P- B2-B3
Advantage 25% only memory addition[less memory]
Drawback: Recovery slow
Fall back:- Refer to the page no:54
Usage: At the time of AMP failure, it permits to access rows in others AMP’S
Party: PID PNM
1 X
2 Y
3 Z
4 M

Advantage: High availability or fast data[At time of failure, immediate redirection to fall back AMP, so that data highly accessible]
Drawback
Note: In real-time we use raid1 and fall back as part of data protection and recovery general we back cluster environment in real-time
Fall back Cluster(3,4,8,16)
Usage: Cluster is nothing but a group of Amp’s, then it takes a single place, where fall back maintain with in the same group
It is an advantage because we will skip scanning other Amp’s And other groups
Note: If 2 Amp’s went down RDBMS halted, Tera data recommend 4 Amp’s for the cluster for detail description refer to page No:55 To get average performance
Journal: Journal is a kind of record, which close some kind of activity
| No. of Amp(N) | Workload1+1/N-1 | Remains should available |
| 16 | 1.06 | 15 |
| 8 | 1012 | 7 |
| 4 | 1.3 | 3 |
| 2 | 2 | 1 |
Single image ![]() one copy of data
one copy of data
Dual image ![]() two copies of the data
two copies of the data
Before image![]() before the change
before the change
Afterimage ![]() after change taking the image
after change taking the image

Usage Once the down Amp came online[repaired] to recovery successfully, recovery journal log are useful
[it helps is to do successful]
Successful Transaction Failed Transaction
BEGIN Transaction;//;Transient _________________ journal activated(T.J)
END TRANSACTION;
1.Drops B. I B. I dropped 1.Roll back happens
2.Discards T.J T.J discarded 2.B.I replied
Note: Transient journal uses before image for its operations
Ex: Till yesterday the data was corrupted
Till yesterday ![]() B.I
B.I
Mon à A.I
|
|
|
Sun ![]() A.I
A.I
Full recovery= B.I+[Mon-Sun] A.I
Selection recovery = B.I+[Mon-This] A.I
Note:- Refer to the material description of example the material

If x=y No, disk input, output error
If x<>y, disk input, output error
Default:- Algorithm applied on data block recording value specified DBC Control utility according to table type
Note:- Many people they using in real-time to implement Change data capturing concepts
Note:-
It is a node, that is a number of cliques that do not configure that execute any tera data vproc if a node in the clique fail
The Amps from the fail node move to the thigh HSN Stand by Node in this way it decreases performance in Zero space zero percentage
You liked the article?
Like: 0
Vote for difficulty
Current difficulty (Avg): Medium

TekSlate is the best online training provider in delivering world-class IT skills to individuals and corporates from all parts of the globe. We are proven experts in accumulating every need of an IT skills upgrade aspirant and have delivered excellent services. We aim to bring you all the essentials to learn and master new technologies in the market with our articles, blogs, and videos. Build your career success with us, enhancing most in-demand skills in the market.

