Business Objects Interview Questions and Answers
What are the differences between Personal, Shared and Secured connections?
- A special connection is created by one user and cannot be used by other users. The connection details are stored in PDAC.LSI folder.
- A shared connection can be used by more users through a shared server. The connection details are stored in SDAC.LSI folder in the Business Objects installation folder. However one cannot set rights and securities on objects in a shared connection. Neither can a Universe to exported to repository using a shared connection.
- A secured connection overcomes these limitations. Through it rights can be determined on objects and documents. Natures can be exported to the key repository only through a ensure connection. The connection parameters in this case are saved in the CMS.
What are custom hierarchies? How can they be created?
Custom Hierarchies are defined in a universe in order to facilitate custom drill down between items from same or different classes according to user requirement. They can be created from Tools --> Hierarchies in the BO Designer.

What is a text in-universe? How are they created?
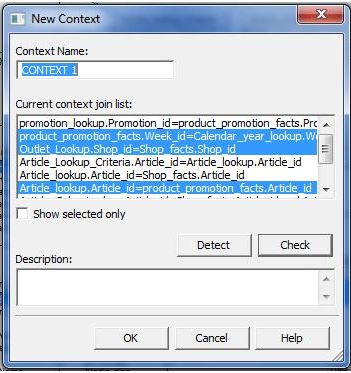
In an universe, a context defines a particular join path between tables or a distinct group of joins for a precise query. Any objects created on a table column which belong to specific contexts is naturally compatible with all other objects from same contexts. When objects from two or more contexts are used, separate SQL is generated and results are then merged in a clone cube. This makes sure that no improper result is generated due to loop or anyone join path issue.
Contexts may be created using detect contexts feature or manually. They are generally created based on logical calculation and business requirements, hence the identify context method is not very effective. To manually create a context Go to Insert Context, give the context name and select the joins that should be present in the context. For a universe contexts should be created in a way that all joins(except shortcut joins) fall in at least one context
What is a chasm device? How can it be solved?
In a dimensional schema based universe, we may have one dimension table joined with two fact tables such that both of them are one-to-many joins(F >- D -<F ). In such a scenario, if we drag a measure each from both the fact tables along with dimensions from dimension table, the value of the measures in the fact tables are inflated. This condition is known as chasm trap.
A chasm trap can be solved using 2 approachs:
- Modern universe SQL parameters, the option, generate multiple inquiries for each measure demands to be selected. This will generate separate SQL statement as each measure and give the proper results. However, this method would not work, if a dimension (for example date) occurs multiple times in the result set due to chasm trap.

- A better path is to put the two joins in two different contexts. This will generate two integrated queries, thus solving the problem.
What is a fan trap? How can it be solved?
In a universe structure, we may have 3 tables joined in such a way that, the 1st table has a one to many join with the 2nd table, which in turn has a one to many join with the 3rd table(A -< B -< C). In such a scenario, if a measure is present in the 2nd table and it is dragged along with any dimension from the 3rd table, the value of the measure will be inflated. Such a condition is known as a fan trap.
A fan trap is solved by creating an alias of the 2nd table and defining contexts such that, the normal table is joined only with the first table, while the alias is joined with both the 1st and the 3rd table. We would take 2nd table’s measure only from the normal table and other dimensions of the 2nd table from the alias table
Should we encounter fan traps in a data warehouse scenario? If so, then how?
If a data warehouse is based on the Kimball model, it is a dimensional schema. In a universe built on that DW, for a fan trap to occur in such a schema, we require direct join between two fact tables, which is against the principles of dimensional modeling.
On the other hand in a data warehouse based on Inmon model, it is a normalized schema. Though in such a case, universes are generally designed on Data Marts, which are dimensional schemas (where fan traps should not occur). However, if a universe is built on the DW (for the purpose of operational reporting), then a fan trap can occur in that universe
What is aggregate awareness? What is its advantage?
Aggregate awareness function is used in scenarios where we have same reality tables in various grains. Using this function we can define only one item for the measures in the fact tables as

We also need to define dimensions for associated granularities and define their incompatibilities with the corresponding facts through the aggregate navigation. This is accesses through Tools -> Aggregate Navigation

The advantage is that in a Webi or Deski report when one drags the measure object with the dimension object of a particular granularity, the measure column from the Fact table of the corresponding granularity is selected in the BO default Query. If we did not use aggregate awareness, we would need to define separate objects for each of the fact tables which would be difficult to understand from a user’s point of view.
What are the 2 different approaches of implementing aggregate awareness? Which one is better in terms of performance?
The 2 approaches are as follows:
- Aggregate tables are built in the database, which contains the dimension fields(not foreign keys) along with the aggregated measures. In the universe they are present as standalone tables, i.e they are not joined with any dimensions. Aggregate aware function is used to define both the dimensions and measures of such tables.
- No aggregate tables are built in the database level. They contain the normal fact table at different granularities. In the universe, aggregate aware is used only to define the measures and aggregate incompatibility is set accordingly.
The first approach is better in terms of performance, since for the higher levels of aggregation, all the information is obtained for a single table. However, a large scale implementation of this approach in a dimensional schema is difficult. In most BI projects, the second approach is preferred
What is a derived table? What is its utility?
A derived table is a table created in the universe using an SQL Query from database level. The columns selected in the query become the columns of the derived table. A derived table can be used for complex calculations, which are difficult to achieve in report level. Such calculations are done in query level itself.
Another use of derived table can be to access tables from a different schema through a dblink.

How is a derived table different from a view? Which one is a preferred solution?
A derived table is present only in the universe level, while a view is created in data base level. Generally views are preferred since, in its case the onus of calculation remains on the database and it does not load the BO server. However, in cases where developers do not have access to database, derived table is the only solution.
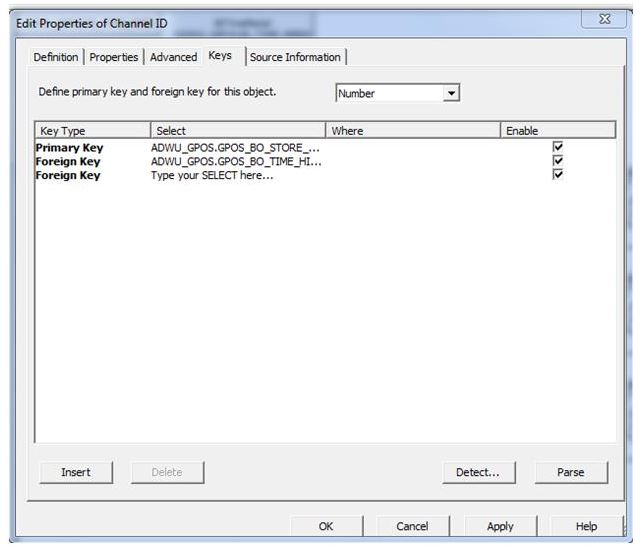
What is Index Awareness? How is it implemented?
Index awareness is a property of the universe, by means of which values in the filter conditions of the queries/data providers built from the universe, are substituted by their corresponding indexes or surrogate keys. Generally the values in the filter condition come from a dimension table (like country etc) and we require a join with the fact table to get this value.
However, if index awareness is implemented, this join is eliminated and the query filter takes the equivalent index value from the fact table itself.
To implement index awareness, one needs to identify the dimension fields which are to be used in query filter. In the Edit Properties of the object, we get a Keys tab. In this tab, the source primary key of the table from which the object is derived needs to be defined as primary key, and the database columns for all foreign key relationships with the other tables also need to be defined here. Once this is done for all required dimensions, the universe will become index aware
How can we use index awareness in universe prompt?
An extended prompt syntax is available since BO 3.1. It is as follows

If the indexes for the dimension object is defined in the universe and we define the prompt condition on the object with the clause ‘primary key’ in place of free or constrained, then the filter condition will convert the prompt values entered to their corresponding indexes and eliminate the join with the dimension table
You liked the article?
Like : 0
Vote for difficulty
Current difficulty (Avg): Medium
About Author

Name
TekSlate is the best online training provider in delivering world-class IT skills to individuals and corporates from all parts of the globe. We are proven experts in accumulating every need of an IT skills upgrade aspirant and have delivered excellent services. We aim to bring you all the essentials to learn and master new technologies in the market with our articles, blogs, and videos. Build your career success with us, enhancing most in-demand skills in the market.
Stay Updated
Get stories of change makers and innovators from the startup ecosystem in your inbox